Daten sind ein wesentlicher Aspekt eines jeden Unternehmens. Sie ermöglichen die Entwicklung von Lösungen, die Verfolgung von Kennzahlen und schaffen eine Struktur für rationalisierte und integrierte Prozesse. Datenanalysen, können, wenn richtig eingesetzt, die Entscheidungsfähigkeit von Unternehmen verbessern.
Dabei gibt es allerdings einen Haken.
Bevor Daten demokratisiert werden können, muss die Infrastruktur dafür existieren. Unternehmen arbeiten deswegen zunehmend daran ihre Dateninfrastruktur zu entwickeln oder Ihre derzeitige IT-Landschaft dahingegen zu aktualisieren.
Nur um das klarzustellen: Niemand sagt, dass das ausgefallenste und teuerste Datenanalyse-Tool verwendet werden muss. Viele Unternehmen, mit denen wir im Projekt DeepScan zusammenarbeiten, nutzen einfache und kostengünstige Lösungen, wenn es um Datenanalyse geht. Insbesondere für mittlere und große Unternehmen stellt die Wahl der richtigen, zukunftsfähigen Lösung allerdings eine thematische Weiche für die Zukunft, mit einem potenziellen Kostenfaktor.
Einer der wichtigsten Entscheidungspunkte ist die Auswahl der richtigen Data Pipeline. Diese Datenpipelines sind es, die Daten in die Data Lakes der Zukunft bringen, Nutzern später zur Analyse bereitstellen und Data Science Teams den Aufbau von KI Use Cases ermöglichen.
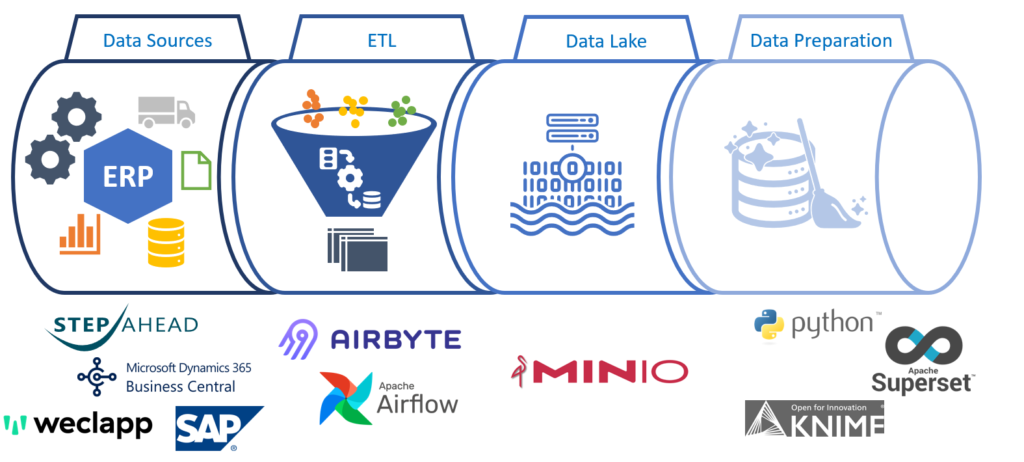
Für unser Projekt Deep Scan wollen wir heute unsere aktuelle Data Pipeline vorstellen. Auch wenn es sich in unserem Fall um den Spezialfall „Forschungsprojekt“ handelt, hoffen wir dennoch einen interessanten Einblick gewähren zu können. Die verwendeten Lösungen sind dabei weder ab vom Standard noch speziell für die Forschung, ganz im Gegenteil, die in der Pipeline verbauten Lösungen orientieren sich am Markt und nutzen aktuellste Anbieter.
Unsere Pipeline startet aktuell mit den verschiedenen Datenquellen, welche in unserem Fall die im ERP-Labor genutzten und von Partnern bereitgestellten ERP-Systeme umfassen. Im ETL Schritt extrahieren wir die relevanten Daten aus den Datenquellen über unterschiedlichste Technologien (SQL, REST-API / ODATA) und transformieren diese in ein fürs Projekt generalisiertes Zielschema. Hierzu kommt maßgeblich Airbyte oder Airflow zum Einsatz. Als Data Lake dient uns Min.io ein Multi-Cloud Object Storage mit S3 Interface. Zur Daten Präparation für die Datenanalysen und Machine Learning Experimente nutzen wir je nach Ziel Superset für die initiale Analyse, Knime und Tableau für einfache Modellierungen und natürlich Python für die weitere Implementierung mit Bibliotheken wie Tensorflow oder scikit-learn.